I rewrote my entire product. Here's the bet.
I wrote about StudyPDF's retention problem, then deleted most of the product and rebuilt it around one idea: the moat is memory, not a smarter model.

Five weeks ago I published my last post. Two weeks later, I deleted most of the product.
That post ended on the one problem I could not crack. People came to StudyPDF for an exam, used it hard for two weeks, passed, and left. Great adoption, terrible retention. I wrote that I had hypotheses and no answers, and that I would come back to it when I had something honest to say.
This is that follow-up. The short version is that the retention problem was not a bug I could patch. It was baked into the shape of the product. So I changed the shape.
What the old product was
StudyPDF 1.0 was a dashboard with buttons. You uploaded a PDF, picked a button, and waited. Flashcards. Mind map. Practice exam. Study guide. Each one was its own page, locked to a single active file, and each one was an all-or-nothing job: a full deck, a complete exam, generated in one go.
The unit of work was the file. The smallest thing you could do was generate a whole artifact. That sounds fine until you look at when people actually showed up.
A full generation is a 30-minute commitment. Nobody makes a 30-minute commitment on a normal Tuesday. They make it the week before an exam. So that is exactly when people used it. Roughly five active days out of thirty, then silence. Around 70% of all returns were driven by an upcoming exam. Between semesters the account carried almost nothing forward. You finished your course, and the product had no reason to still matter to you.
You cannot fix that by adding a seventh button. The exam-cycle was not a missing feature. It was the natural result of making the smallest possible interaction so expensive. I could have spent the whole year polishing artifacts and the retention curve would have looked exactly the same.
The bet
I kept coming back to one thing. A model that turns a PDF into flashcards is not a moat anymore. ChatGPT can do it. Gemini can do it. Students were telling me so in the surveys, plainly: "I just use Gemini now." Every month that gap closed a little more.
So what is actually defensible? Not the model. The memory.
ChatGPT is amnesiac by design. Every chat starts from zero. It does not know which lecture you are on, what you got wrong last week, or what your professor actually emphasized. It cannot build a picture of you across a semester, because it throws that picture away at the end of every conversation.
That is the one thing I can build that a general chatbot structurally cannot. A per-student, per-course picture of what you know that compounds over weeks and semesters.

Two design choices fell out of that, and neither was negotiable.
First, scope everything to a course, not a file. Knowledge should accumulate. Upload lecture three on top of lectures one and two, and the product should get smarter about your course, not just hand you another isolated deck. That accumulation is a switching cost. ChatGPT cannot match it, because it never had your first two lectures.
Second, lead with conversation, not buttons. The entry point had to drop from a 30-minute commitment to a 30-second one. "Quiz me on lecture three." "What mattered most in this one?" Small asks, any day of the week. The goal was to turn five days every thirty into one or two days a week, all semester long.
What Bo is
So I rebuilt the whole thing around a single agent. Its name is Bo.
Bo is scoped to one course at a time. You talk to it. It answers using your own uploaded lectures, and when you ask for something bigger, it builds that thing inside the conversation instead of sending you off to another page. Ask a question, get an answer. Ask for a practice exam, watch it get made. The study materials are the same kinds as before (flashcards, quiz, exam, study guide, cheat sheet, summary, mind map), except now they are things Bo makes while you talk to it, not buttons you go hunting for. And when a lecture has a diagram, it does not get left behind. Bo crops the real figure and drops it onto the card.
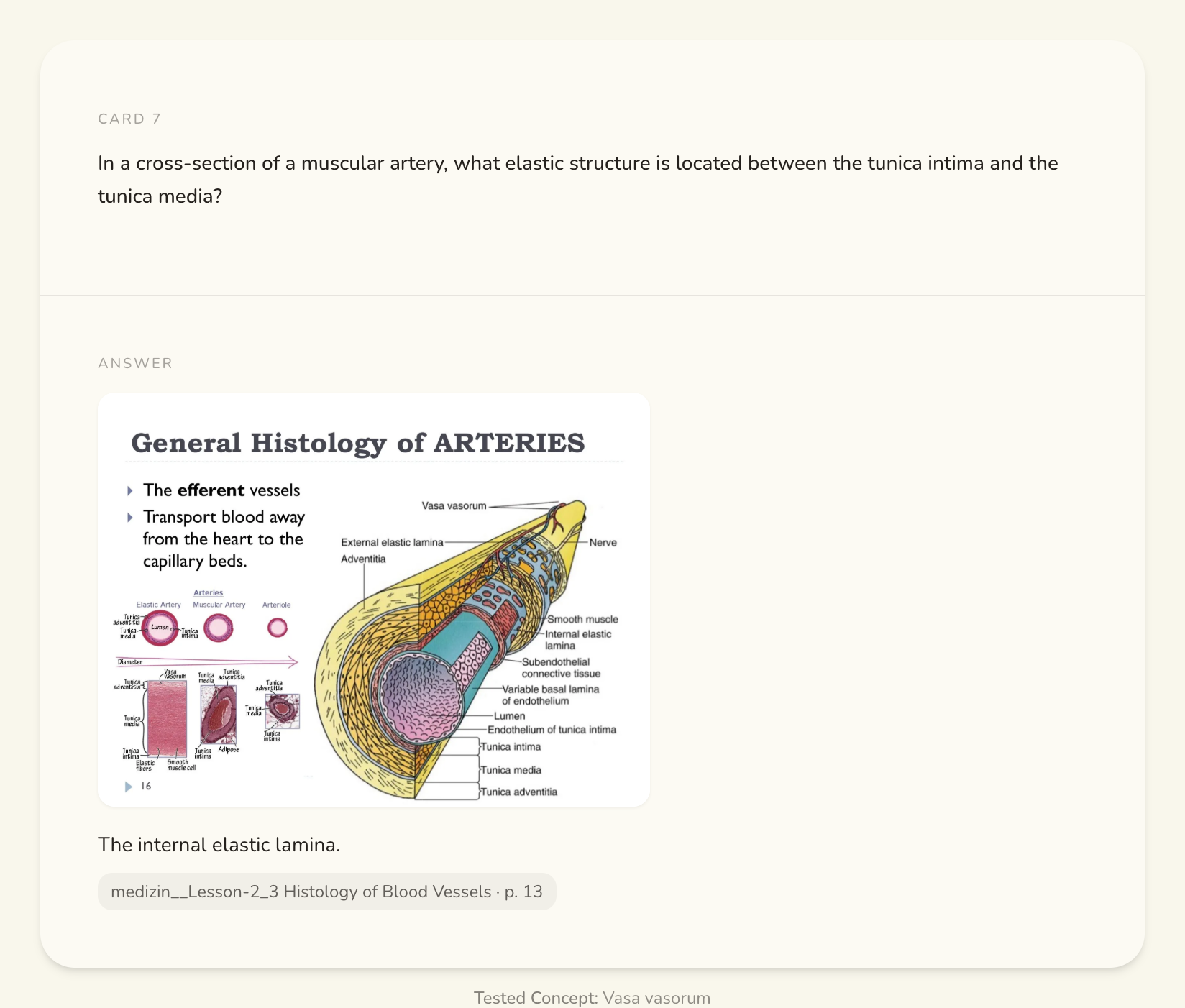
This card embeds the artery cross-section straight from the lecture it came from, cited to the page. You study the exact figure from your own slides, not a redrawn copy.
Here is Bo running one full workflow, start to finish, in about fifty seconds:
The launch film. I made it myself with the app's own motion-video engine, because solo means the trailer is also your job.
The one rule I would not bend is grounding. Bo does not make things up about your material. Ask about something that is not in your lectures and it says so and stops, instead of inventing a confident answer. Under the hood Bo does not even retrieve on its own. A separate Researcher agent searches your course, and every concept or figure that ends up in an artifact is taken from those verified results, never from the model's own prose. A final step scrubs anything the model invented that is not actually in your material. Citations point back to the lecture and the page.

This was the single most requested thing in my surveys. Students do not trust a study tool that might quietly be wrong, because they cannot tell when it is wrong. So Bo would rather say "I don't see that in your course material" than guess.
The one deep read
Everything I just described leans on a piece I built into the old product about a year ago and kept. One expensive read, reused by everything.
When you upload a course, a reasoning model reads all of it once and pulls out the structure. The topics. The concepts inside each topic. How they connect. That graph is stored at the course level and de-duplicated across lectures, so lecture five knows it is talking about the same idea that lecture two introduced.
Every flashcard, every exam question, every answer Bo gives points at a specific concept in that graph. And every time you study, the interaction writes back. You got this concept right, you stumbled on that one. That running record is the mastery layer. It is the per-student picture I bet the whole rewrite on.

The shape of it is the point. The expensive part happens once, in the middle. Bo and all seven artifact kinds hang off that one graph, and the mastery layer feeds back into it. ChatGPT can make you a flashcard. It cannot do this, because it does not keep the graph and it does not remember you between chats. That is the moat, drawn out.
What broke
A rewrite this size does not go clean. Two stories.
The first one cost me two outages and about a week of my life. Starting June 8, the API server kept getting killed by the kernel for running out of memory. Thirty-something times. The obvious suspect was upload concurrency, too many big PDFs landing at once, so I added semaphores to throttle it. The kills kept coming. One of them tripped the host's restart limit and took the whole thing down a second time.
It was not concurrency. It was two unrelated things wearing the same costume. One was the PDF rasterizer turning a handful of pathological files into enormous images with no size cap. The other was an infinite loop in the text chunker that only fired on transcripts with no page markers (think a long YouTube lecture) past about 320,000 characters. Its termination check could never become true, so it appended the same tail chunk over and over until memory ran out. The bug everyone assumed was a scaling problem was a loop that could never end. Once both were fixed, peak memory dropped from 20GB spikes to about 2GB, and the kills stopped.
The second story is the honest one, because it is about the part I cared most about being quietly broken.
The mastery layer, the thing the entire bet rests on, was silently starving for weeks. Around 94% of artifacts were saving with no concept links at all. The chat tracking was failing more than half the time without making a sound, because an earlier commit meant to "stop it from crashing" had hidden the errors instead of fixing them. I "fixed" it more than once. Each time, I checked again a day later and found it still broken in a new place. It took a real rewrite before the numbers held. Zero-concept artifacts fell from about 87% to 18%, and chat rejections from about 49% to 6%. I confirmed it in production on June 17, then checked it again the next morning, because by then I had learned not to trust the first green.
If you read the last post, these rhyme with the old war stories. The holiday I spent debugging vector-store contamination. The three 2am nights during an internship when every new signup hit a broken onboarding loop. Same lesson, bigger system. Solo means the thing that breaks at the worst possible moment is also the thing only you can fix.
Did the bet work?
That is the real question, and it deserves its own post with the actual numbers, which I am still letting settle. The honest preview: the early data surprised me, and one of the things I was most sure of turned out to be wrong in an interesting way. Retention moved. Just not where I had aimed it.
More on that next, once I have watched it hold for a few clean weeks.
If you are building in applied AI, solo or close to it, I would like to hear from you. Find me at studypdf.net, luishenrich.com, or @luisnhenrich on X.